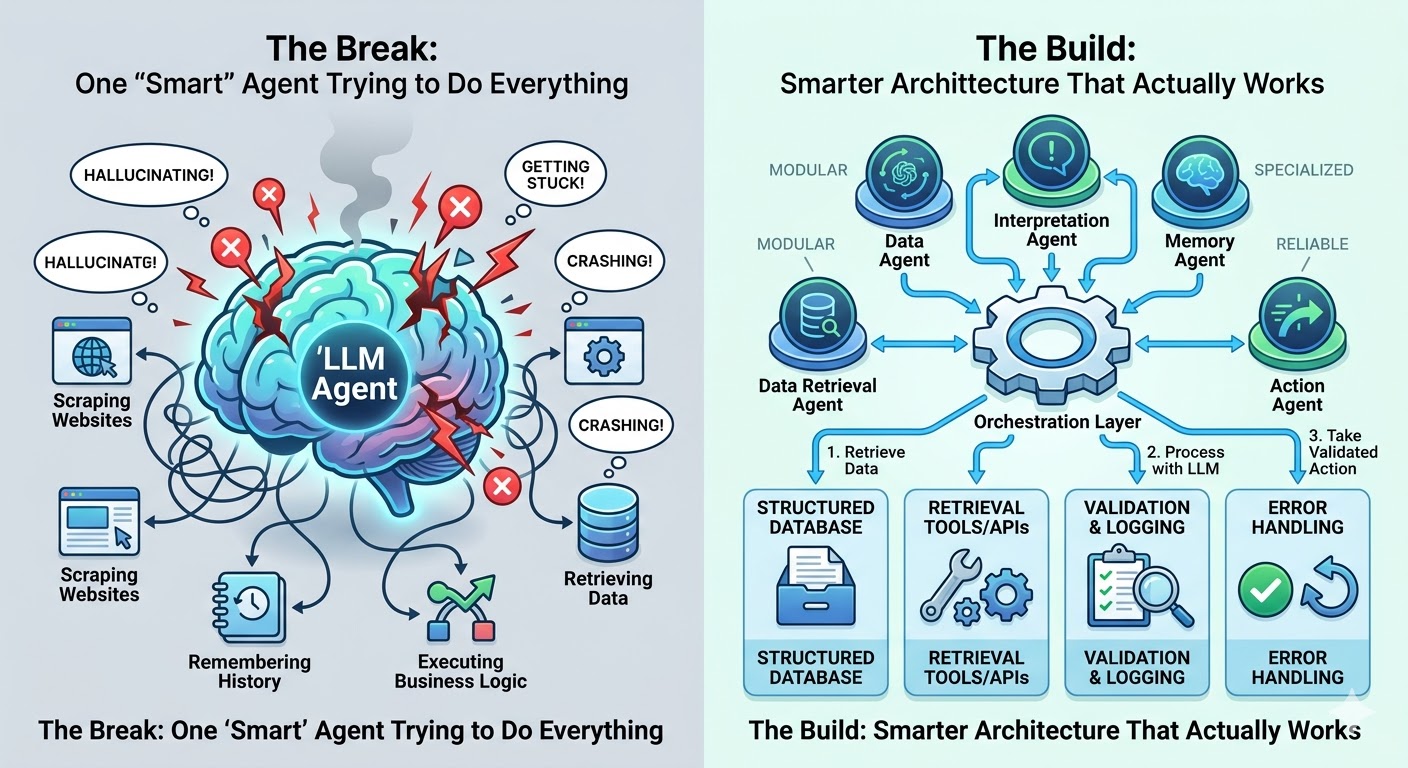
Every week, another business announces they're building an AI agent. Yet teams routinely discover their agents hallucinate data, get stuck in loops, crash when something unexpected happens, or simply stop working after a few real-world interactions.
The core issue isn't the technology itself — it's architectural decisions. Most teams take a powerful language model, write detailed prompts, and expect it to handle everything from data retrieval to decision-making. This approach works in demos but fails in production.
Successful businesses don't use smarter prompts; they use smarter architecture.
LLMs Are Not Workhorses
Language models excel at understanding and generating language, interpreting ambiguous instructions, and reasoning through complex problems. However, they aren't designed to serve as operational backbones.
Most businesses assign a single AI model to scrape websites, store structured information, execute business logic, manage workflows, and make decisions simultaneously. This creates predictable failures:
Web browsing unreliability: Models may fabricate results, return outdated training data, or fail silently when tasked with pulling current website information.
No data storage: Each conversation starts fresh without explicit memory infrastructure. Asking models to "remember" across sessions without proper database layers causes lost context and inconsistent behavior.
Inappropriate business logic: Pricing calculations, compliance checks, and conditional workflows require precise, repeatable code — not prompts that drift unpredictably.
The solution involves assigning the AI model a defined, limited role and building the right tools around it to handle everything else.
Memory Is Not One Thing
A critical architectural mistake treats memory as a single problem. Instead, well-built agent systems require four distinct memory layers:
Structured Memory: The database layer holding facts, records, user data, and transaction history with precision and accuracy. This should never exist inside the AI model itself.
Conversational Memory: Context from ongoing interactions — what the user said, earlier decisions in the session. This must be explicitly managed and passed to the model deliberately.
Semantic Memory: Finding relevant information based on meaning rather than keywords through Retrieval Augmented Generation (RAG). This approach retrieves relevant documents and feeds them to the model when needed, offering superior accuracy and control.
Identity Memory: Knowledge about who the system works with over time — preferences, history, role, permissions. This creates coherent, personalized experiences across multiple sessions.
Collapsing these layers into one prompt creates unpredictability. Separating them builds reliability.
Stop Using AI to Retrieve Data
Retrieval represents one of the most misunderstood aspects of AI system design. Many teams default to having the AI model find information, introducing systematic errors.
Language models don't retrieve data; they predict text. When asked to "look something up," models generate plausible-sounding answers based on training data — often inaccurate and rarely signaling uncertainty.
The correct approach separates retrieval from interpretation entirely:
- Use deterministic tools (scrapers, APIs, database queries) for retrieval, yielding exact, predictable results
- Bring in the AI model afterward for interpretation, summarization, matching, or reasoning over accurate data
- This separation enables debugging — you can trace whether failures occurred in retrieval or interpretation stages
Reliable AI systems are built on reliable data pipelines. The model is the last step, not the first.
One Agent Trying to Do Everything Will Fail
Building one powerful agent handling entire workflows end-to-end feels simpler but creates fragile architectures. Single agents force every task to compete for the same context window, instructions, and decision processes. Early mistakes compound without isolation or recovery mechanisms.
The superior approach uses small, specialized agents with a clear orchestration layer above them — like managing a team where individuals handle specific roles and a manager coordinates their work.
Specialized agents provide:
- Narrow, well-defined jobs (data retrieval, summarization, decision routing)
- Easier building, testing, and repairs
- Contained failures with clear root causes
- An orchestration layer that decides which agent gets called, in what order, with specific inputs
This requires more upfront work but remains the only approach sustaining complexity growth.
Error Handling Is the Real Differentiator
Most AI system discussions focus on prompts and consistency. However, systems fail primarily because nobody built a plan for when things go wrong.
Production environments guarantee failures: API timeouts, unexpected model outputs, empty retrieved documents, unhandled user inputs. These aren't edge cases — they're certainties.
Solid error handling involves three elements:
Retries: Temporary failures (network hiccups, API outages, overloaded services) resolve automatically with proper retry logic. Without it, systems stop dead.
Validation: Checking that received outputs match expectations before acting. Malformed model outputs or incomplete data get flagged before downstream damage occurs.
Logging: Making systems knowable over time. Good logs show exactly what happened, when, and why — separating teams improving systems from those fighting perpetual fires.
Better prompts make your system smarter in ideal conditions. Error handling makes your system trustworthy in real ones.
What This Means for Your Business
Building functional AI agents requires sound architectural decisions before writing code, not finding the most powerful model or perfect prompt.
Successful businesses share common practices:
- Assign models defined, limited roles
- Separate memory into appropriate layers
- Use deterministic tools for retrieval, letting AI handle interpretation
- Build with small, specialized agents instead of fragile monoliths
- Treat error handling as core requirements, not afterthoughts
This approach demands clarity, structure, and contingency planning — the same rigor applied to serious business infrastructure.
For businesses evaluating AI automation or facing reliability problems, the issue is almost never the model itself. It is the architecture around it.
Ready to build AI systems that actually work?
Book a free 30-minute call with our team. We'll examine what you're building, identify breaking points, and discuss making it reliable. No pitch, no pressure — just a straightforward conversation about your system.
Book a Call